Redis 没有直接使用 C 语言传统的字符串表示(以空字符结尾的字符数组,以下简称 C 字符串),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象 类型,并将 SDS 用作 Redis 的默认字符串表示。
SDS的定义:
每个 sds.h/sdshdr 结构表示一个 SDS 值: struct sdshdr { // 记录 buf 数组中已使用字节的数量 // 等于 SDS 所保存字符串的长度 int len; // 记录 buf 数组中未使用字节的数量 int free; // 字节数组,用于保存字符串 char buf[]; };
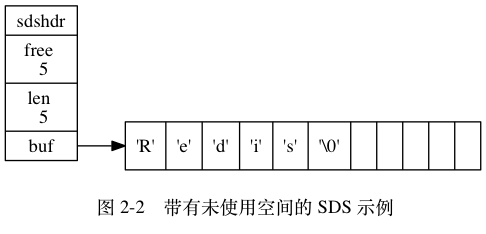
这个 SDS 为 buf 数组分配了五字节未使用空间, 所以它的 free 属性的值为 5 (图中使用五个空格来表示五字节的未使用空间)
SDS 遵循 C 字符串以空字符结尾的惯例, 保存空字符的 1 字节空间不计算在 SDS 的 len 属性里面, 并且为空字符分配额外的 1 字节空间, 以及添加空字符到字符串末尾等操作都是由 SDS 函数自动完成的, 所以这个空字符对于 SDS 的使用者来说是完全透明的。
为什么遵循空字符结尾? 因为这样SDS 可以直接重用一部分 C 字符串函数库里面的函数。
- 如果程序执行的是增长字符串的操作, 比如拼接操作(append), 那么在执行这个操作之前, 程序需要先通过内存重分配来扩展底层数组的空间大小 —— 如果忘了这一步就会产生缓冲区溢出。
- 如果程序执行的是缩短字符串的操作, 比如截断操作(trim), 那么在执行这个操作之后, 程序需要通过内存重分配来释放字符串不再使用的那部分空间 —— 如果忘了这一步就会产生内存泄漏。
因为内存重分配涉及复杂的算法, 并且可能需要执行系统调用, 所以它通常是一个比较耗时的操作。为了避免 C 字符串的这种缺陷, SDS 通过未使用空间解除了字符串长度和底层数组长度之间的关联: 在 SDS 中, buf 数组的长度不一定就是字符数量加一, 数组里面可以包含未使用的字节, 而这些字节的数量就由 SDS 的 free 属性记录。
通过未使用空间, SDS 实现了空间预分配和惰性空间释放两种优化策略。
空间预分配用于优化 SDS 的字符串增长操作: 当 SDS 的 API 对一个 SDS 进行修改, 并且需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。
若修改后字符串长度 len < 1MB,=> free=len;反之, free=1MB。所以如果字符串修改后扩展为长度为5字节,那么5+5+1(‘\0’)=11字节。
惰性空间释放用于优化 SDS 的字符串缩短操作: 当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。 SDS 也提供了相应的 API , 可以释放 SDS 里面的未使用空间, 所以不用担心惰性空间释放策略会造成内存浪费。
二进制安全
C 字符串中的字符必须符合某种编码(比如 ASCII), 并且除了字符串的末尾之外, 字符串里面不能包含空字符, 否则最先被程序读入的空字符将被误认为是字符串结尾 —— 这些限制使得 C 字符串只能保存文本数据, 而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
因此, 为了确保 Redis 可以适用于各种不同的使用场景, SDS 的 API 都是二进制安全的(binary-safe): 所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据, 程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的, 它被读取时就是什么样。
虽然 SDS 的 API 都是二进制安全的, 但它们一样遵循 C 字符串以空字符结尾的惯例: 这些 API 总会将 SDS 保存的数据的末尾设置为空字符,并且总会在为 buf 数组分配空间时多分配一个字节来容纳这个空字符, 这是为了让那些保存文本数据的 SDS 可以重用一部分